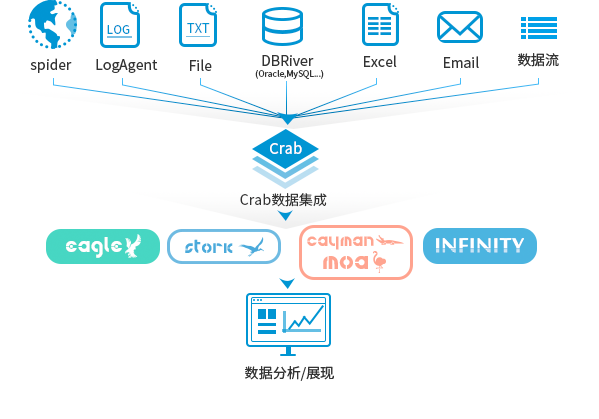
提供可跨异构数据存储系统、数据库、文件、日志、网页、实时流数据的集成解决方案。可靠,安全,低成本,可弹性扩展, 并实现智能调度与监控有效帮助您解决异构数据存储系统的数据互通难题,让您数据不再成为孤岛!助您实现大数据分析和实时数据智能。

自主研发的强大的网络爬虫系统,通过部署配置动态抓取相关网页信息,通过控制台轻松部署项目列表,通过设置抓取策略实时监控项目状态。
将传统的业务数据从源端经过抽取、转换、加载至目的端,支持多种数据源和抽取策略。
支持text、tail、syslog、exec、concole、RPC等不同日志源数据的采集,同时对这些数据进行简单处理后存储到后端。

支持多目录实时监控、自定义属性和策略收集非结构化数据。
客户端文件系统:同步客户端、虚拟磁盘;
支持操作系统文件收集:Linux、Windows、Mac OS;
支持移动端文件收集:Android、IOS;
支持应用系统通过消息队列实时将数据导入
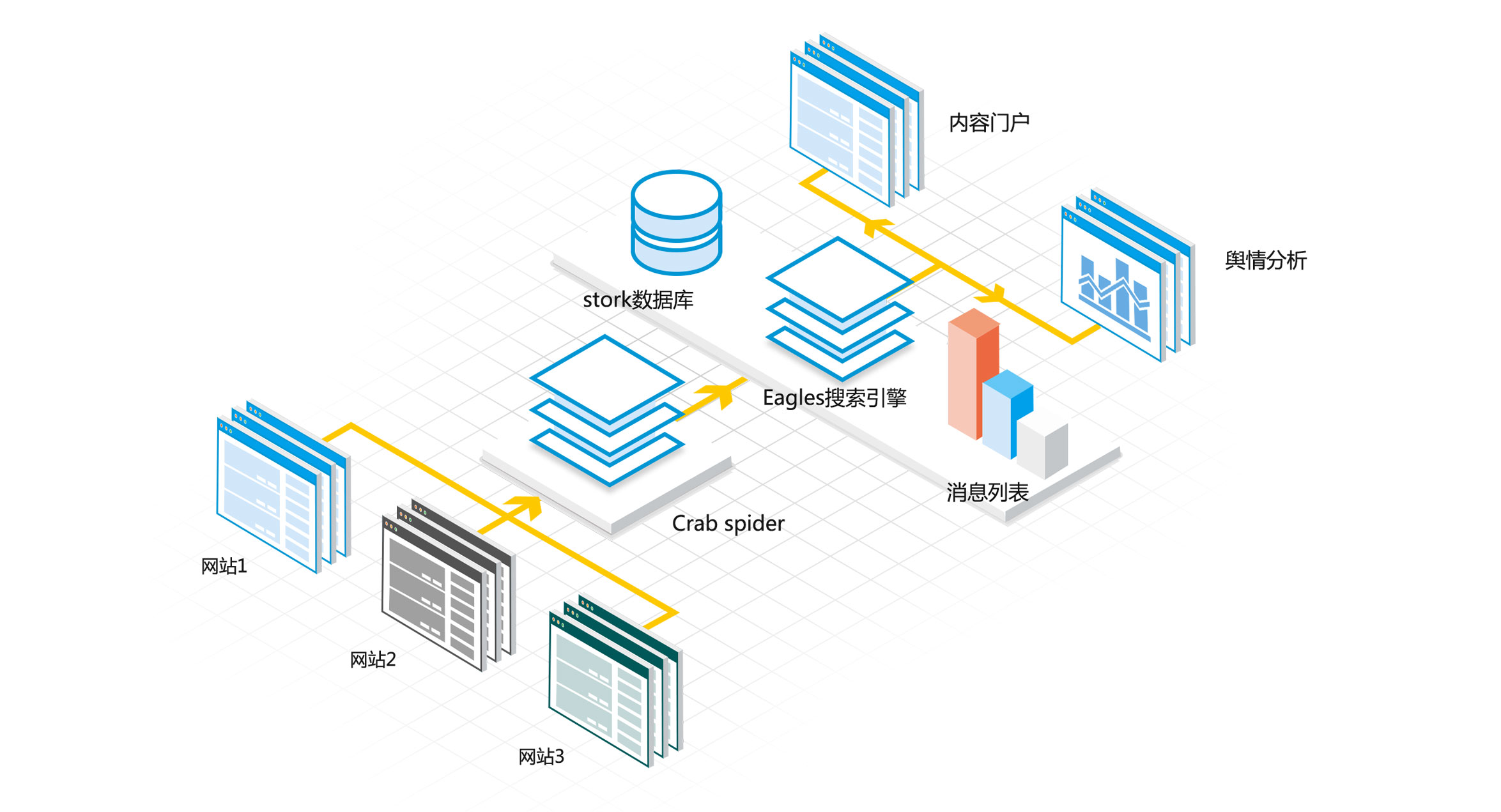
通过DANA Crab大数据融合引擎,可以帮助开发者快速进行网页爬虫系统开发。提供上手简单,灵活开放的爬虫云开发环境,让开发者只需要在线写几行Python代码就可以实现一个网站爬虫。并且爬虫将自动运行在DANA平台服务器上,爬取速度更快,效率更高。
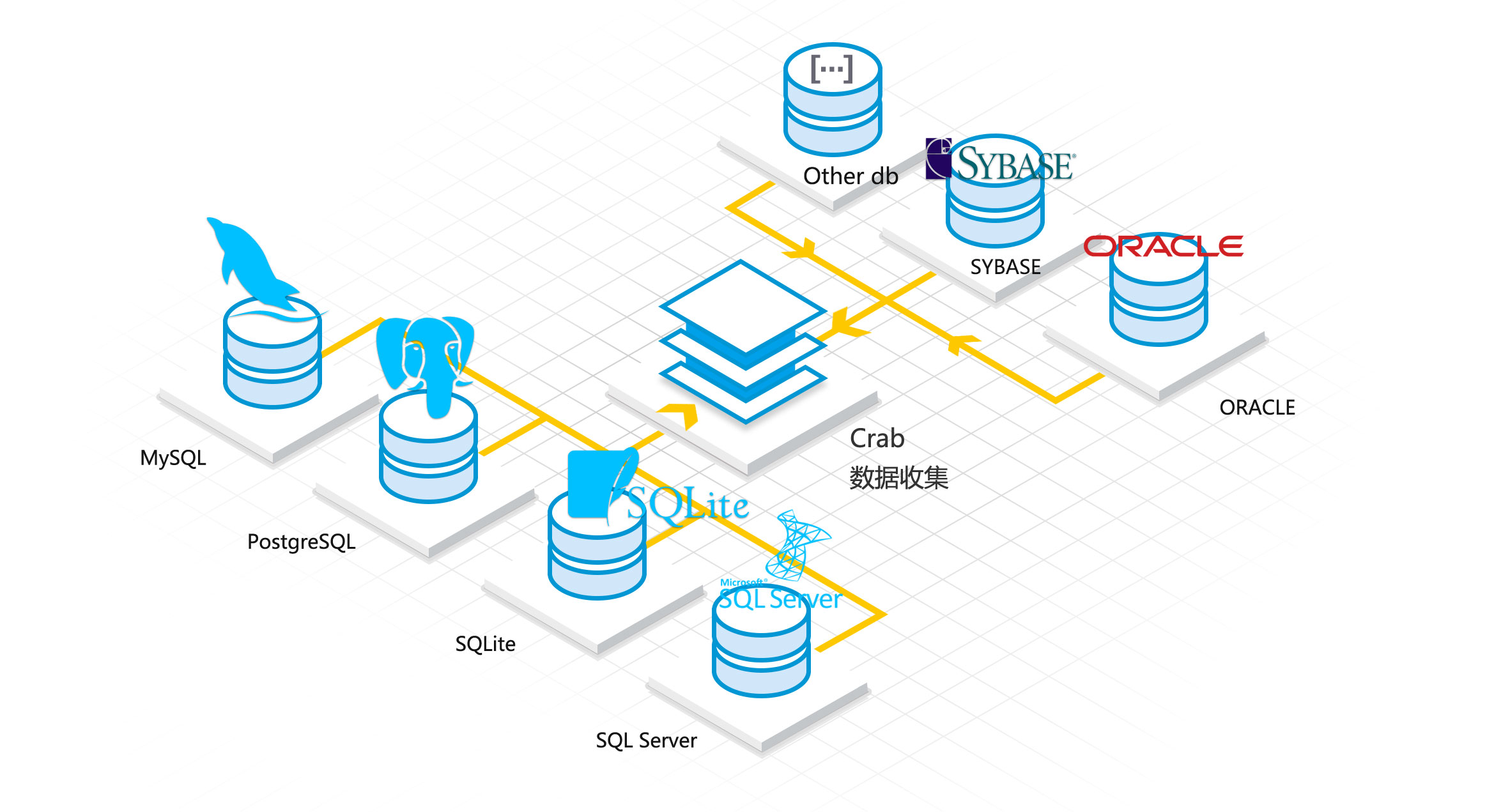
Crab引擎支持多种数据库源的抽取,常见的oracle, mysql, sqlserver, postgres, db2, sybase都能很好的支持, 目标存储同样支持所有数据库类型,还支持Phoenix消息引擎、Eagles引擎、Teryx数据库等目标。抽取任务调度使用Dodo任务调度系统配合使用。
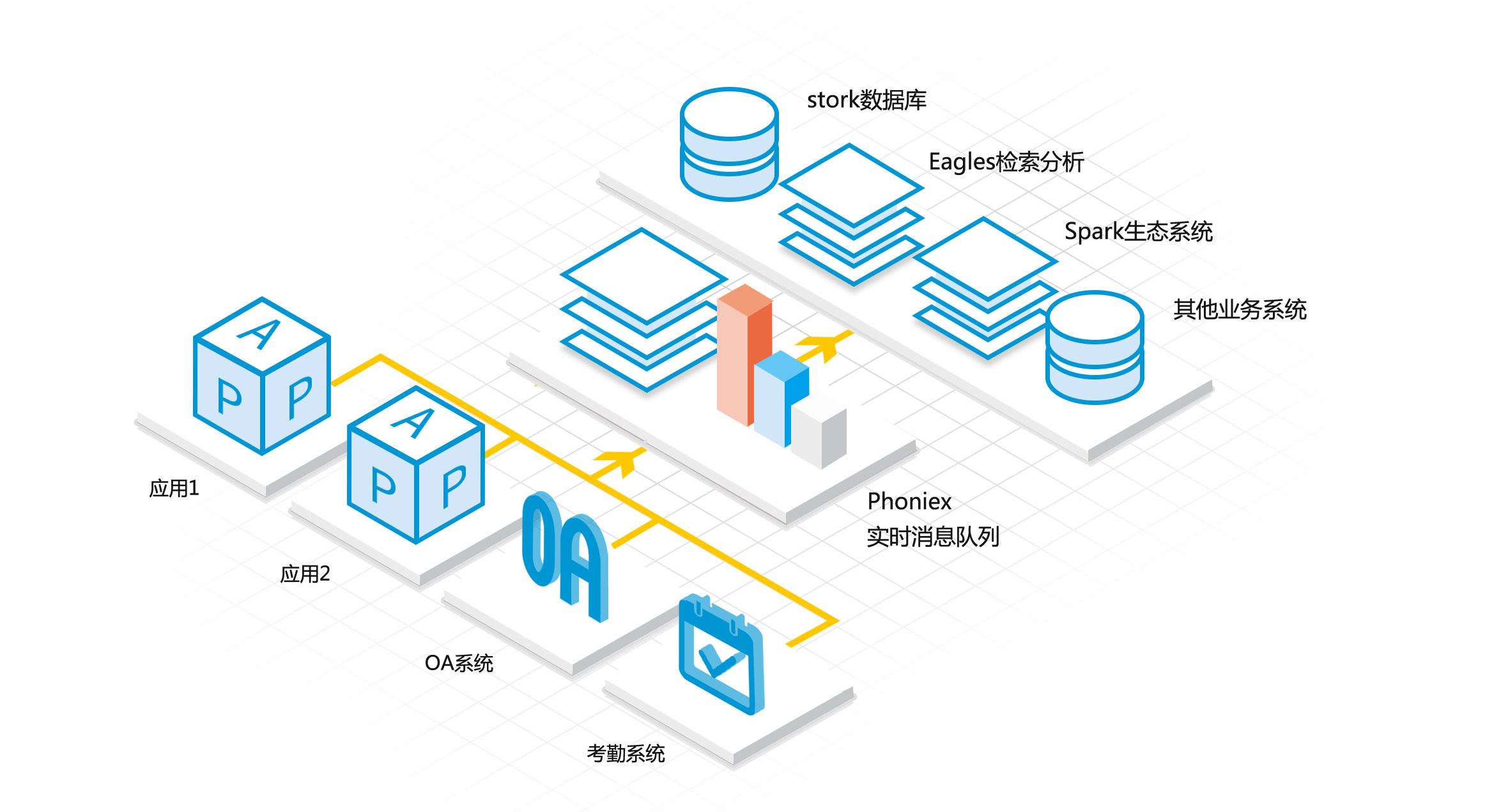
Crab引擎通过Phoenix消息中间件引擎,封装实现了Kafka标准协议 & RESTFul API 接口形式的实时数据汇聚通道,Phoenix作为传输中介队列,满足 100w+/s 的高吞吐需求。