
D-Mining大数据计算分析平台包含多个大数据开发套件,主要包括:


性能怪兽:对比Mysql、DB2等传统关系型数据库,对比Mysql、DB2等传统关系型数据库,数据在TB级别的查询效率提高了千倍,支持实时并发查询,支持千亿级别数据的实时分析。
零学习成本:采用Restful Api发送请求,SQL或者Query DSL语法进行分析,零学习成本上手大数据实时分析。
功能强大:支持地图GEO、文本内容全文搜索,插入数据字段类型自动识别,自动建表建字段,打破传统数据库使用局限。
实时索引:新数据实时刷新、自动建索引,无需后台等待,实现毫秒级实时分析统计最新数据。
安全堡垒:通过多年大数据项目的经验积累,我们可以做到在发生节点迁移、挂多节点、甚至挂集群的情况下,依旧保证您的数据始终安全如一。
性能怪兽:对比Hadoop MapReduce,简单分析快千倍,复杂分析快百倍;对比Spark-Sql,简单分析快十几倍。
发体验友好:开完全兼容SQL 2003标准,支持 Select、From、Join 等标准 SQL 语法,以及 Count、Sum、GroupBy 等分析函数。
全托管平台:在线编写SQL查询作业开发、调试、运维、定期调配。
打破存储壁垒:拥有RDD资源共享池,可关联查询不同库的数据,包括Eagles、Stork、Hdfs、Hive、Hbase、Mongodb、Mysql,摆脱数据分散存储烦恼。


性能怪兽:百万吞吐量,计算可达毫秒级延迟,让流计算真正规模化、实时化。
强兼容性:兼容通用的聚合函数、流数据、静态数据关联查询、自定义UDF函数,您可以任意拓展业务逻辑,完全兼容Spark原生应用。
全托管平台:提供在线开发平台,集成流式任务开发、调试、运维。
性能怪兽:对比Hadoop MapReduce计算方式,计算性能可提升百倍。
算法繁多:提供几十种常用算子,完全兼容spark原生分布式算子函数。
多语言支持:兼容多种开发语言,包括Scala、Python等等。
全托管平台:在线编写多种复杂计算作业、开发、调试,一键保存运行。
无忧调度:完善的定时调度策略,可设置分、时、天等各种复杂调度。
全程监控:作业执行状况、历史执行记录、历史执行日志一览无遗。


算法多样:百种常用算法,分类展示,覆盖回归,分类、聚类,文本分析等问题,并支持业界常用深度学习框架,满足不同层面的需求。
模型丰富:集结德拓大数据项目上的多种算法模型,包括多维度用户画像、刑侦嫌疑人判别、交易反欺诈模型、文本挖掘等模型。
多语言支持:提供R语言、Scala、Python方式开发,无需重复学习一门新语言。
全托管平台:在线编写、调试、运行、运维,无需关注开发环境问题。
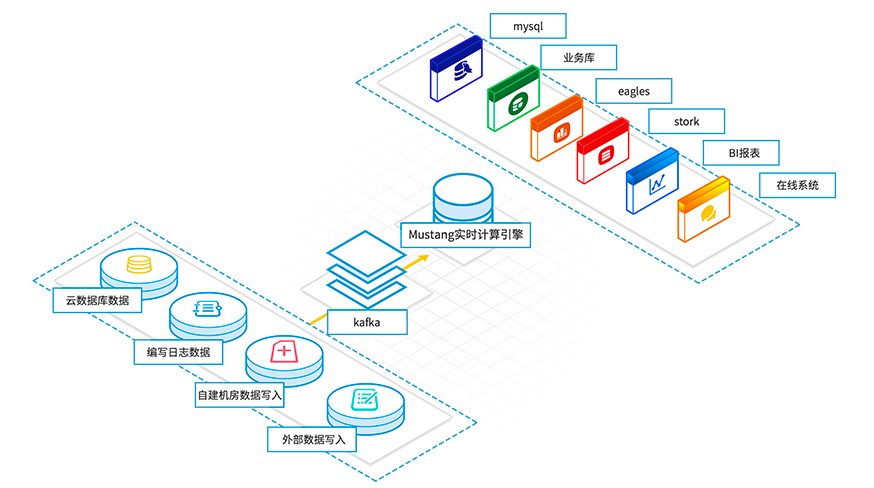
共享单车投放后,需要实时监控排查是否有问题单车,并且分析热点区域,最大化投放收益,提升服务品质。利用地图搜索加上业务逻辑处理,显示问题单车位置,及时回收,同时实时分析早晚高峰单车资源分配情况,给予智能调控。
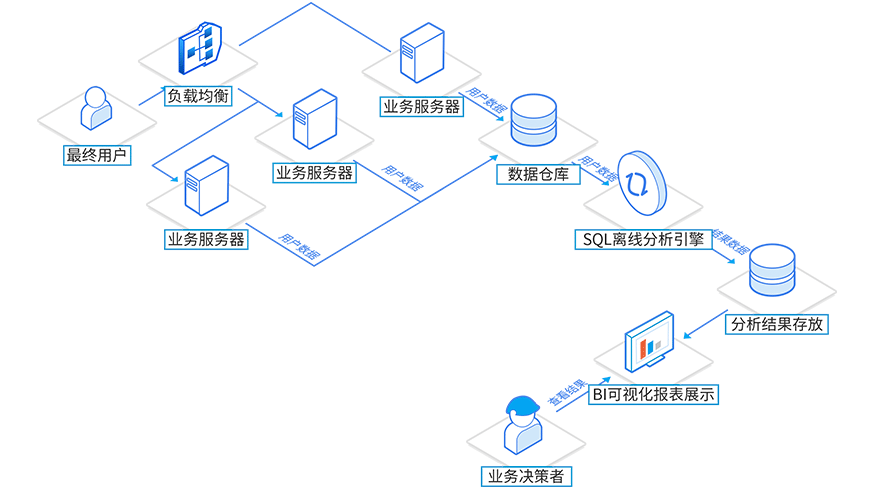
从千万级用户数据中往往可以提取出宝贵信息以指导业务决策,包括广告投放设定、内容优化方案等等。D-Mining SQL离线分析可以为在线视频厂商提供Spark等成熟技术框架用于用户数据分析服务,实现海量用户数据分析。
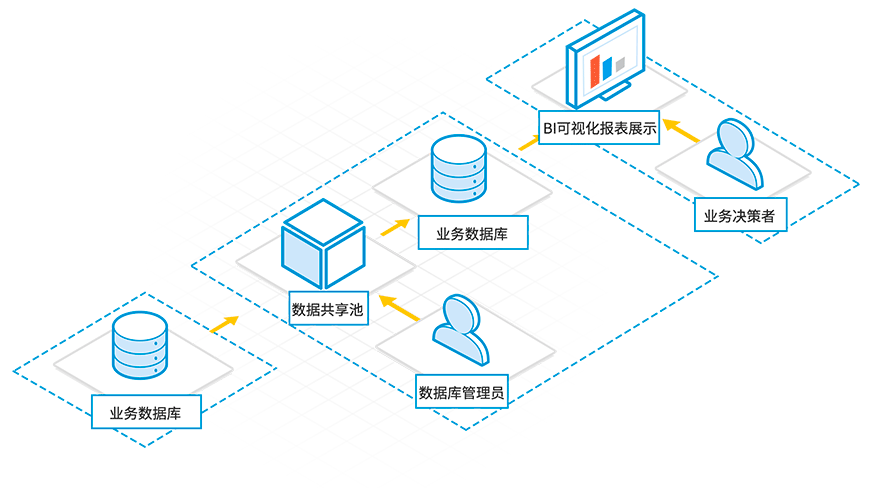
SQL离线分析获取数据源(Eagles、Stork)中的数据,基于SQL 2003查询语法进行OLAP分析,将大数据分析结果配置导出到 (Eagles、Strok) 以此服务于上层业务系统,帮助企业快速完成海量数据的经营分析,生成报表提供决策支持。
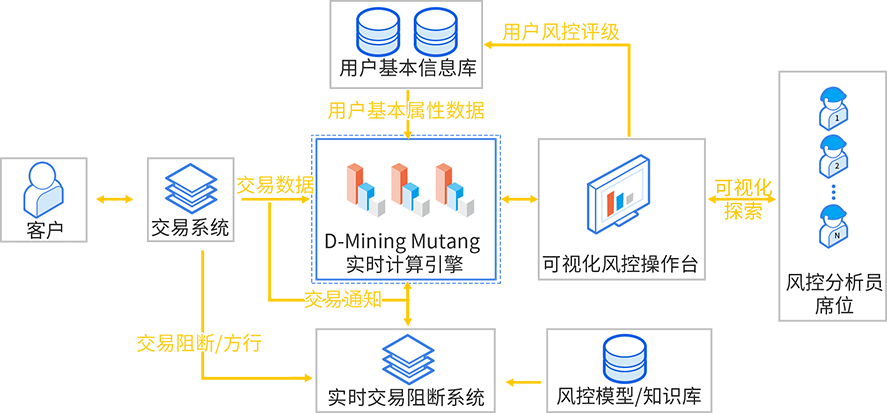
利用 API/SDK,金融客户在其交易系统中把用户交易流水数据实时同步到D-Mining Mustang实时计算引擎中,再结合用户基础属性数据,风控分析员团队将通过可视化风控操作台以实现对用户交易行为的实时探索分析,并对相关交易风险做出判断,形成实时交易判别风险系统,同时结合所积累的风控模型/知识库,以及 D-Mining Mustang实时计算所提供的海量数据毫秒级数据分析能力,对用户交易行为进行实时研判,及时阻断客户的可疑交易操作,搭建实时交易阻断系统。
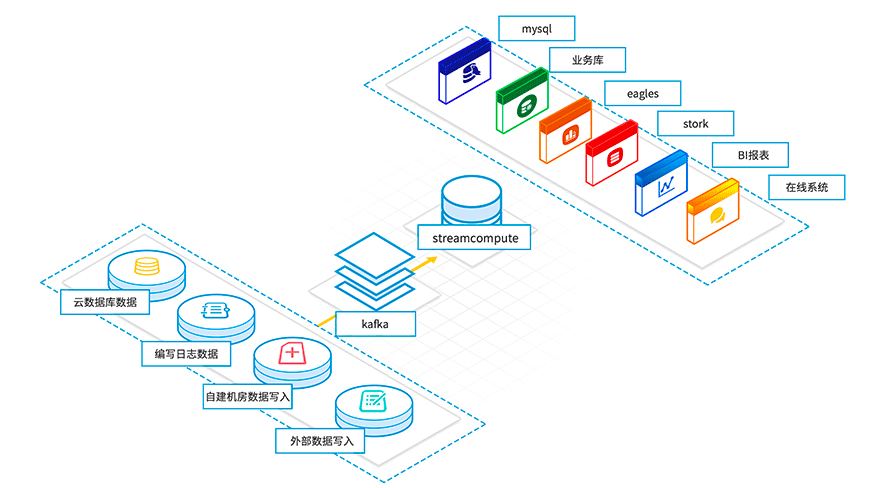
实时计算获取消息队列(Phoenix,Kafka)中的日志信息,获取各个服务、应用的日志,对日志进行加工分析、监控,遇到问题提前处理或报警,为应用、服务良好运行提供了安全保障,大大降低运营风险。
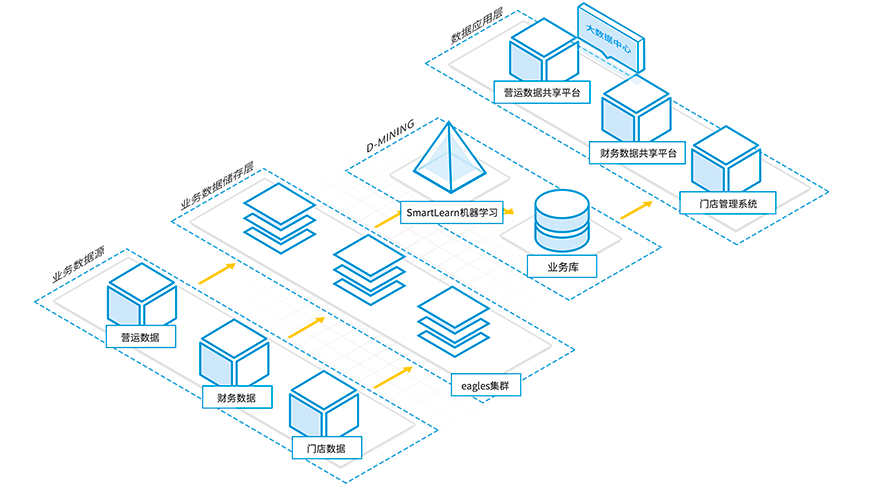
利用大数据提高会员服务的体验,利用众多业务数据对会员的分类、分级、偏好进行分析,最终形成会员的用户画像,在针对连锁门店的经营状况等数据进行分析,以增加对会员行为预测的更准确的判断,最终针对不同用户采用不同的经营策略和精准营销,提升服务品质。




