

在数据采集、数据交换、数据同步、数据合并、数据整合、数据迁移、数据仓库建设等领域有广泛的使用。
任何完整的大数据平台,一般包括以下的几个过程:
● 数据采集
● 数据存储
● 数据处理
● 数据展现
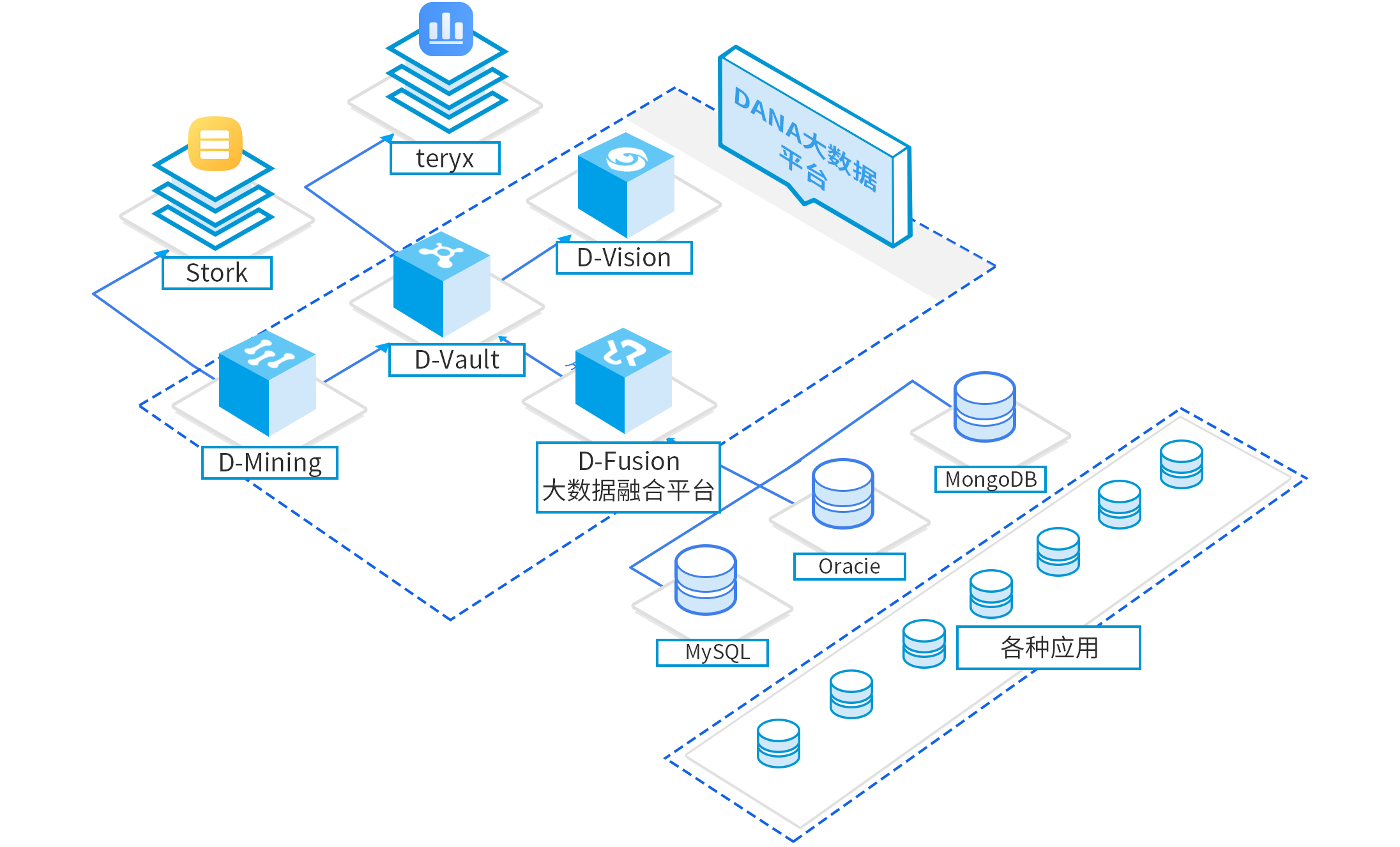
● 经过几年积累,D-Fusion目前已经有了比较全面的插件体系。
● 主流的RDBMS数据库、NOSQL、文件、日志、网页集成都已经接入。
● 每一种读插件都有一种或多种切分策略,都能将作业合理切分成多个Task并行执行,单机多线程执行模型可以让抽取速度随并发成线性增长。DANA团队对所有的已经接入的插件都做了极致的性能优化,并且做了完整的性能测试。
● 抽取作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是D-Fusion的基本要求,在D-Fusion 3.5的设计中,重点完善了框架和插件的稳定性。目前可以做到线程级别、进程级别、作业级别多层次局部/全局的重试,保证用户的作业稳定运行。
● D-Fusion针对常用的数据源抽取提供了向导式开发,针对复杂流程任务也支持拖拽式配置任务流程,简单清晰的表达抽取任务。
● D-Fusion数据融合平台抽取支持非常多种类的目标数据库、文件系统,oracle, Stork, Teryx, Eagles等。
● 同时在流计算场景,通过实时消息队列,完美的和D-Mining大数据计算分析引擎对接。


分钟级策略配置,支持复杂cron表达式。

支持数据库/文件系统的全量抽取和增量抽取。

兼容标准的Kafka协议。

内置RESTFul网关代理,支持给每个Kafka Topic创建独立代理,支持多节点并发。

通过部署配置动态抓取相关网页信息,通过控制台轻松部署项目列表,通过设置抓取策略实时监控项目状态。

支持复杂流程的ETL抽取,一键提交分布式调度框架执行。

支持跨平台日志采集代理,自定义复杂日志采集规则,支持正则表达式,日志增量收集等特性。

产品提供了丰富数据转换的功能,让数据在传输过程中可以轻松完成数据脱敏,补全,过滤等数据转换功能,另外还提供了内置公式函数,也可以让用户自定义处理脚本。
● 支持SQL脚本
● Javascript/Shell脚本
● 公式函数

● flume
● collectd
● sqoop等
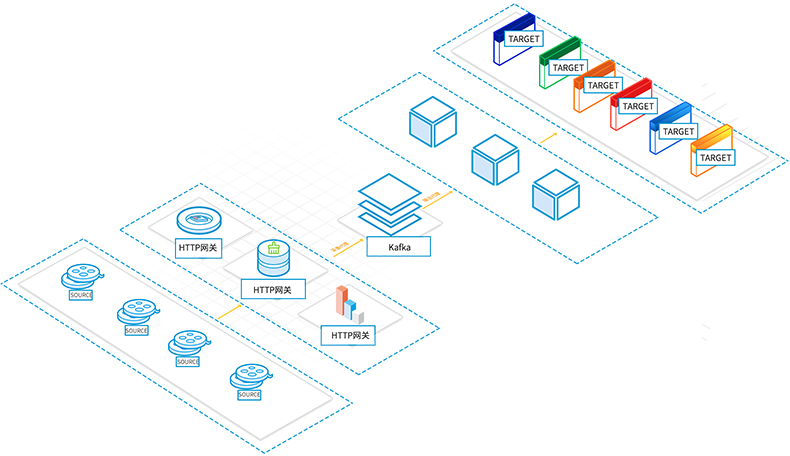
D-fusion内置实时消息引擎,兼容标准Kafka标准协议,同时支持配置HTTP/TCP 等协议代理网关,Scale-out水平扩展,高性能,满足100w+/s性能的高吞吐场景需求。
主要用于各种RDMS,Mongodb,Hbase等数据源数据同步,定时抽取、过滤加工等业务场景。

通过DANA Crab大数据融合引擎,可以帮助开发者快速进行网页爬虫系统开发。提供上手简单,灵活开放的爬虫云开发环境,让开发者只需要在线写几行Python代码就可以实现一个网站爬虫。并且爬虫将自动运行在DANA平台服务器上,爬取速度更快,效率更高。
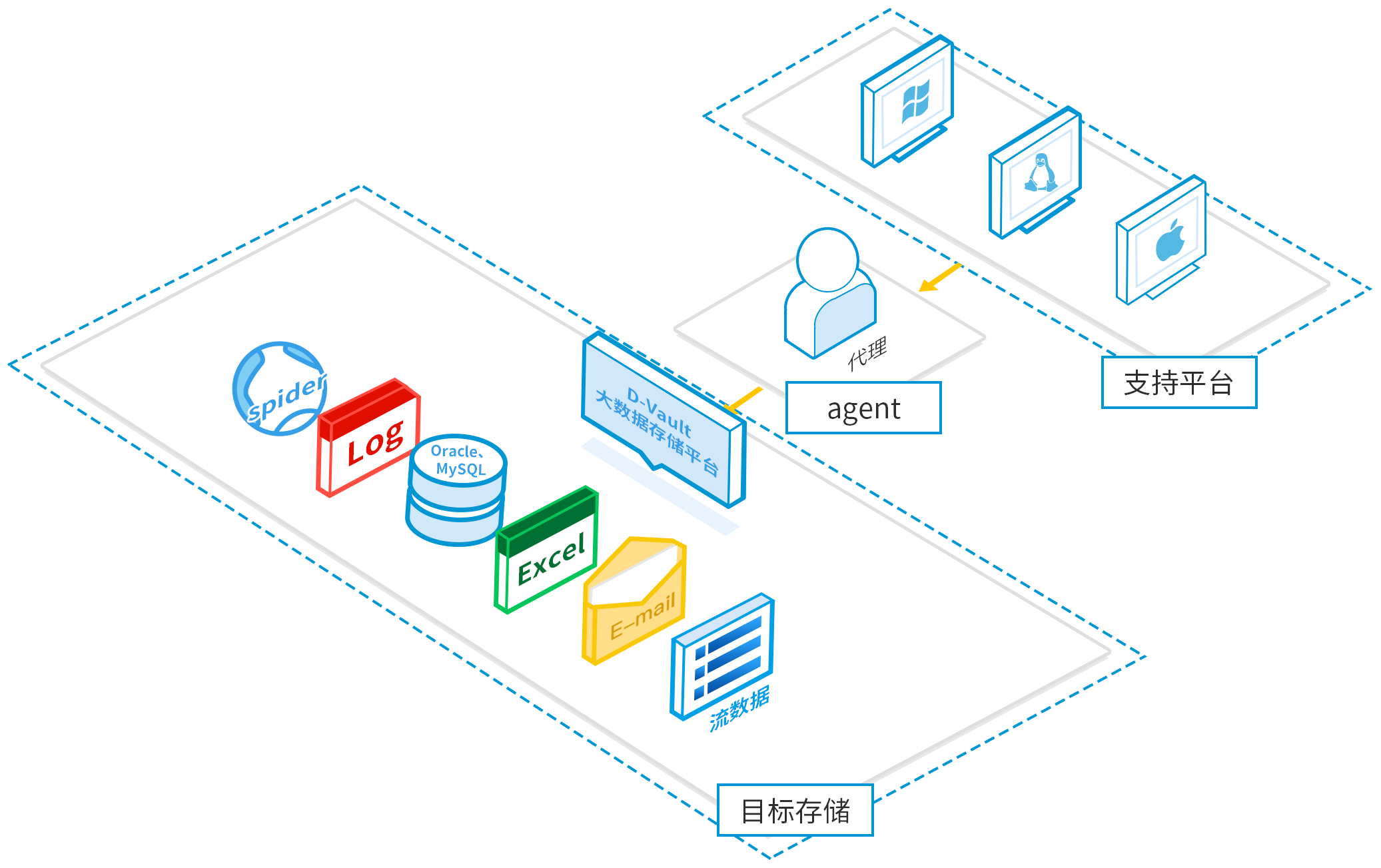
支持Mac、linux,windows三种类型客户端,支持在客户端操作系统上按照一个代理agent,即可完成文件的定时、准实时文件收集,采集目标存储。




